FAIR Challenge
The FAIR Challenge benchmarks several recent methods for facial albedo estimation from in-the-wild images.
To participate in our challenge, please check the Download page to get the benchmark data.
Leaderboard
Dataset construction
The FAIR benchmark dataset is constructed using 206 high-quality 3D head scans purchased from Triplegangers1. The scans were selected to cover a relatively balanced range of sexes and skin colors (ITA skin group). Ages range from 18 to 78 years old. All of the scans were captured under neutral expression and uniform lighting, which we treat here as approximate ground-truth albedo. We obtained UV texture maps compatible with FLAME [39] by registering the FLAME model to the scans using the approach in [39].
We used 50 HDR environment maps from Poly Haven2 covering natural and artificial lighting. In each scene, we rendered three head scans under the same illumination. To ensure a balanced distribution of skin types, each image was constructed by randomly selecting a skin type and then randomly selecting a sample scan within the type.
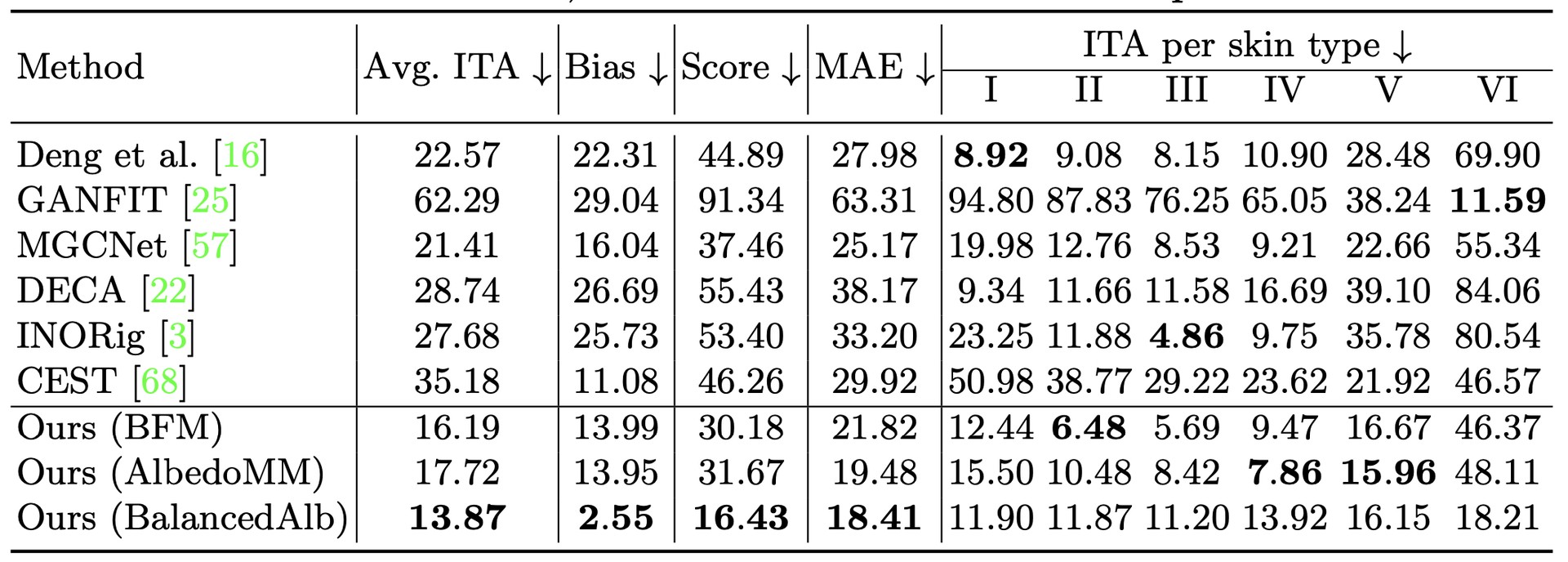
Evaluation metrics.
We focus on both accuracy and fairness and hence propose to use the following metrics:
- ITA error. We compute the fidelity of skin tone by taking the average error in ITA (degrees, see Eq. 1) between predicted and ground-truth UV maps, over a skin mask region (see Sup. Mat.). We report average error per skin type (I to VI) and average ITA error across all groups.
- Bias score. We quantify the bias of a method in terms of skin color by measuring the standard deviation over each per-group ITA error (note that this is not the same as the standard deviation over the full dataset). Lower values indicate less bias since here the method would perform equally for all groups.
- Total score. We summarize average ITA and bias scores into a single score, the sum of the two.